Exploring Adversarial Machine Learning
tl;dr I would recommend this course to anyone who wants a more than surface level technical (read: needs to be able to code) course about a variety of methods to use to attack ML systems.
Some Context
I’ve been a penetration tester for about three years, but my experience with machine learning (ML) has been pretty limited — aside from some basic data engineering courses in university. I write Python scripts for automation and the occasional tool during my day to day, but I’m no software engineer.
In hindsight, I should have taken the Getting Started with Deep Learning course first. This course does a great job explaining the fundamentals with supporting materials, but I spent extra hours researching because I lacked a solid foundation.
 Math is hard
Math is hard
The Course
Alright, with that out of the way, let’s break down the course structure and my thoughts on each section. The course is hands-on, meaning you’re not just reading theory—you’re running code, experimenting with attacks, and seeing results in real-time. That was probably the best part.
Each section focuses on a specific class of ML security attacks, providing explanations, attack demos, and exercises to reinforce learning. The balance between code and theory felt well-structured, but some sections were quite dense (especially if, like me, you didn't take the recommended prerequisites).
Evasion
Generating a sample to intentionally get misclassified while preserving some other property (such as human imperceptibility).
We go through open box and closed box levels of access, and various attacks such as Carlini and Wagner L2 method, SimBA, and HopSkipJump. The course does link to the papers behind these methods and provides boilerplate code to help out.
This is the first section of the course, and oh boy was it dense. There is a lot of material to cover. However being able to run code, and see it work in real time, is very satisfying.
✅ Key Takeaways:
- The basics of evasion through random perturbations
- How to implement more nuanced attacks, balancing efficiency and tradecraft
- Understanding the differences between targeted and untargeted evasion attacks
- Optimizing attacks to be more effective and stealthy
- Attacking models in both open and closed box conditions, depending on the access level
Extraction
Using queries to build a functionally equivalent model. This section teaches you how to extract a model or replicate its functionality using query-based techniques. It covers various methods to reverse-engineer a model’s behavior, including real-world attacks like Proof-Pudding. There’s a focus on practical attacks that are especially relevant in cybersecurity, where extracting models can pose serious security risks.
The course provides little tidbits like the following.
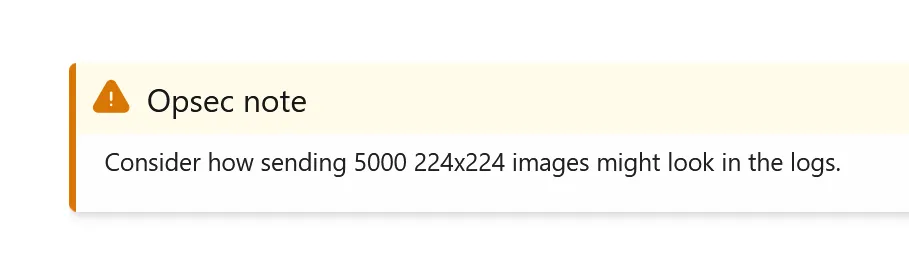
✅ Key Takeaways:
- The concept and techniques behind extraction attacks
- How to extract an image recognition model
- Running the Proof-Pudding attack (CVE-2019-20634) and understanding its impact
- The value of extracting models for cybersecurity purposes, especially for adversarial defense
Security Assessments
This section goes over the various tools, and libraries that exist to make security assessments against ML systems easier, and efficient. I didn't know any of these tools and libraries prior to undertaking the course. As a result I did spend a fair amount of time familiarising myself with them.
✅ Key Takeaways:
- Applying theoretical attacks to assess real-world ML security
- Using the Adversarial Robustness Toolbox to attack local models and remote endpoints
- Generating adversarial text using TextAttack
- How to use Alibi for explainability... and how explainability can be a useful security tool.
- How to think about ML and ML security problems as optimisations.
- How to apply Optuna for hyper-parameter optimisation.
Inversion
Inversion is the process of inverting a model in order to get a representation of the training data.
✅ Key Takeaways:
- How to perform a basic inversion attack by finding an input that maximizes a particular output.
- How to build a custom loss function that uses domain specific knowledge to improve the simple inversion attack.
- How to use AIRT tools to automate inversion attacks against models.
- Attack a more realistic model and see where the basic attacks begin to fail, and how to explore parameterization of the attack to improve it.
- An example of extracting data from diffusion models.
Poisoning
class of training-time attacks designed to influence decisions made by the final model
Poisoning attacks are designed to affect a model’s training process by subtly corrupting the data it learns from. This section covers how to manipulate training data to influence model behavior, including methods like data poisoning and algorithmic poisoning. You’ll also dive into Witches’ Brew, a 2021 poisoning attack that targets test images by altering their gradients during training.
✅ Key Takeaways:
- Understanding different poisoning attack vectors (Training time attack vectors, Data poisoning by hand, Algorithmic data poisoning) and how they can be used during training
- The theory behind Witches’ Brew and how it uses gradient descent to manipulate test image classification
- Hands-on experience creating poisoning attacks that manipulate models' behaviour at training time
Large Language Models (LLMs)
LLMs that we all know and love. One piece that stuck out was the following mindset:
...LLMs shouldn't get a pass because it's AI! There are many such concerns, but stick to your roots, don't be confused by the math, focus on the system and mechanics!
The course introduces prompt injection attacks and has an exercise exploiting a vulnerable version of LangChain's LLMMathChain to achieve remote code execution.
Then we go through a simple data poisoning attack against GPT-2. It creates a poisoned training set by inserting a trigger word into a subset of the Alpaca instruction dataset that makes the model ignore the instruction and just repeat the input. After fine-tuning on this poisoned data using PEFT, it evaluates the attack effectiveness.
From here we walk through an implementation of the Extracting Training Data from Large Language Models paper. The course shows how to generate text samples from GPT-2, score them using techniques like perplexity, compression, and casing to identify potentially memorized training data. There are exercises to experiment with generation methods, scoring functions, and prompts to try to extract specific information that may have been memorized during training.
✅ Key Takeaways:
- Understanding prompt injection and remote code execution attacks on LLMs (with LangChain)
- Poisoning GPT-2 training data to influence its outputs
- How to detect memorized data in LLMs using techniques like perplexity and compression
- Exercises to extract specific information from LLMs by manipulating prompts and scoring models
Course Assessments
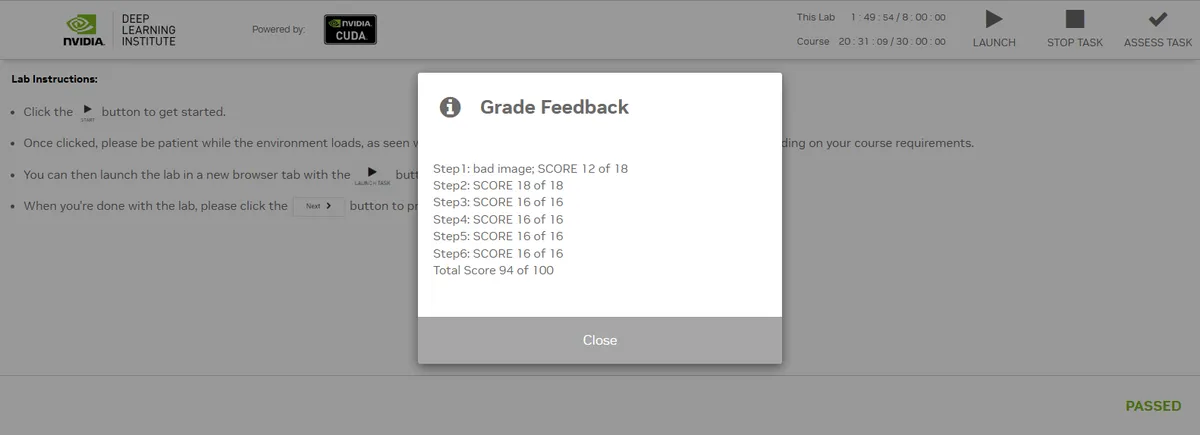
To earn a certificate, you’ll need to complete an assessment for each major topic, applying what you’ve learned to solve real-world problems. The assessments come in the form of six different notebooks, each covering a major course area.
The assessments were challenging, but not impossible. I had a few difficulties, but the folks on the NVIDIA forums were very helpful in pointing me in the right direction.
 https://learn.nvidia.com/certificates?id=vjbxm1AKQ06da6hu80bHtw
https://learn.nvidia.com/certificates?id=vjbxm1AKQ06da6hu80bHtw
Closing Thoughts
Do I feel like an AI Red Teamer now? Not quite. It feels like I followed a recipe and baked a cake, but I only really understand what flour is — whilst my knowledge of the other ingredients is still developing.
That said, I learned a ton from this course, and I’ll definitely be going back through my notes. If you’re interested in ML security and aren’t afraid of coding, this is absolutely worth your time. Feel free to reach out if you have any other burning questions about this course.
Going forward, I'll be spending some time on Dreadnode's platform, Crucible. It was created by Will Pearce, who was one of the people behind this NVIDIA course.